


The 164th Block: Fact-checking, still important
Sometimes, we all need a reminder

This week…
Your reading time is about 7 minutes. Let’s start.

For people whose work revolves around creating and publishing (words, sounds, visuals, etc.), there is an understandable reluctance to finalise the product because once it’s out there, you can’t really make modifications (arguable). I realised this when I was the producer of Speak Easy, a spoken word poetry programme for BFM Media. Most of the poets we had on the show were stage poets, although some were also published poets. When I asked those who aspired to publish “maybe one day,” many disclosed how much they enjoyed the dynamics of performing their pieces live, where no one poem would ever be experienced the same way, but felt that once a poem is on a page, it gets eternalised in that form, no take-backsies (arguable).
Don’t be mistaken; they understand the arguability of their reasoning. But I think if you use your Instagram Stories more than your feed (or whatever the parallels are on other social media platforms), then I’m sure you can empathise.
Anyway, two days ago, Matthew Engel wrote a piece for The Guardian about the Major League Baseball series between the Chicago Cubs and St Louis Cardinals played in London this weekend. The London “world tour,” the second time it has happened, is part of the league’s plan to grow overseas. Unfortunately, the piece provided incorrect figures — the type that anyone can easily double-check online. That night, I wrote in and received a response from the editor almost immediately.
The correction notice, which you can read at the bottom of the article, will give you an indication of how some veterans in legacy media sometimes take the fundamentals of fact-checking for granted, just like us nobodies. It could be the kind of facts and figures you get wrong at the first draft (arithmetics isn’t for everyone, and the rules of MLB change all the time), but not the kind of error that should slip through editing and get into publication, especially when the information is provided on the MLB’s site.
So be kind to yourself. You probably hold yourself to a higher standard than industry veterans and legacy institutions.
And now, a selection of top stories on my radar, a few personal recommendations, and the chart of the week.
ICYMI: The Previous Block reviewed Maria Ressa's reservations about the “Reuters Institute Digital News Report 2023.” CORRECTION NOTICE: None notified.Humans are biased. Generative AI is even worse

An excellent interactive piece by Leonardo Nicoletti and Dina Bass for Bloomberg:
To gauge the magnitude of biases in generative AI, Bloomberg used Stable Diffusion to generate thousands of images related to job titles and crime. We prompted the text-to-image model to create representations of workers for 14 jobs — 300 images each for seven jobs that are typically considered “high-paying” in the US and seven that are considered “low-paying” — plus three categories related to crime. We relied on Stable Diffusion for this experiment because its underlying model is free and transparent, unlike Midjourney, Dall-E and other competitors.
[…]
The analysis found that image sets generated for every high-paying job were dominated by subjects with lighter skin tones, while subjects with darker skin tones were more commonly generated by prompts like “fast-food worker” and “social worker.”
Categorizing images by gender tells a similar story. Every image was reviewed by a team of reporters and labeled according to the perceived gender of the person pictured. For each image depicting a perceived woman, Stable Diffusion generated almost three times as many images of perceived men. Most occupations in the dataset were dominated by men, except for low-paying jobs like housekeeper and cashier.
Try it out and see it for yourself. The interactive bit is further down the article.
How non-Western journalists enriched coverage of the global pandemic
Mahima Jain and Jennifer Ugwa spoke to journalists and fact-checkers from Kenya, Nigeria, China, Peru, Colombia, and the Philippines for The Open Notebook:
There was the language issue, of course: The world’s 8 billion people speak over 7,000 languages, yet English is the lingua franca of science and scientific research, and many other languages lack even the terminology to convey science’s more complicated technical concepts. But newsrooms also had to bridge the social and cultural divides that often separate the science world from the communities they serve. Meanwhile, they were battling an infodemic of false and misleading claims, which spread across borders, continents, countries, and into even the most remote communities almost as quickly as the virus itself.
In time, [Lalit Khambhayata] (now a news editor at the newspaper Divya Bhaskar) came to see these challenges as opportunities. He sensed that the Gujarat Samachar’s readership had a clear appetite for scientific discourse on the rapidly evolving pandemic. And he saw openings to use knowledge of his community’s shared culture and history to bridge information gaps. In one story, he used an incident from the life of lawyer and Indian freedom fighter Mahatma Gandhi, a Gujarati native, to explain the historical significance and importance of quarantining. Gandhi, who quarantined in South Africa during the plague of the late 1800s, “wrote a full chapter on quarantine in his autobiography,” Khambhayata explains.
Khambhayata is one of countless journalists throughout the Global South who found ways to cover the pandemic with clarity, compassion, and cultural fluency under trying circumstances.
How to prepare for the deluge of generative AI on social media

Sayash Kapoor and Arvind Narayanan on Knight First Amendment Institute:
But what, exactly, is new? Bad actors with expertise in Photoshop have long had the ability to make almost anything look real. It’s true that generative AI reduces the cost of malicious uses. But in many of the most prominently discussed domains, it hasn't led to a novel set of malicious capabilities.
How significant is the cost reduction?
Read on. Long read, though, but worth your time.
What I read, listen, and watch…
I’m reading Charlie Guo’s guide to writing great ChatGPT prompts. Clean and clear.
I’m listening to Scott Galloway’s piece on techno-narcissism, as read by Goerge Hahn.
I’m watching Tammy Beaumont’s double-century first innings (and Sophie Ecclestone’s 10-wicket haul by the end of Australia’s second innings) at the Women's Ashes. Phenomenal.
Other curious links:
“‘A sense of betrayal’: liberal dismay as Muslim-led US city bans Pride flags” by Tom Perkins for The Guardian.
“The 1970s librarians who revolutionised the challenge of search” by Monica Westin for Aeon.
“The media cares more about the Titanic sub than drowned migrants” by Alex Shephard for The New Republic.
“New resource helps journalists choose appropriate language for their reporting” by Sarah Scire for IJNet. Vox Media’s “Language, Please” is available here.
“¿La presunción de inocencia está en crisis?” por Oriol Solé Altimira en elDiario.es.
« Lecture artificielle et ‹vol› de voix : l’IA bouleverse le monde des livres audio » par Eloïse Duval dans Libération.
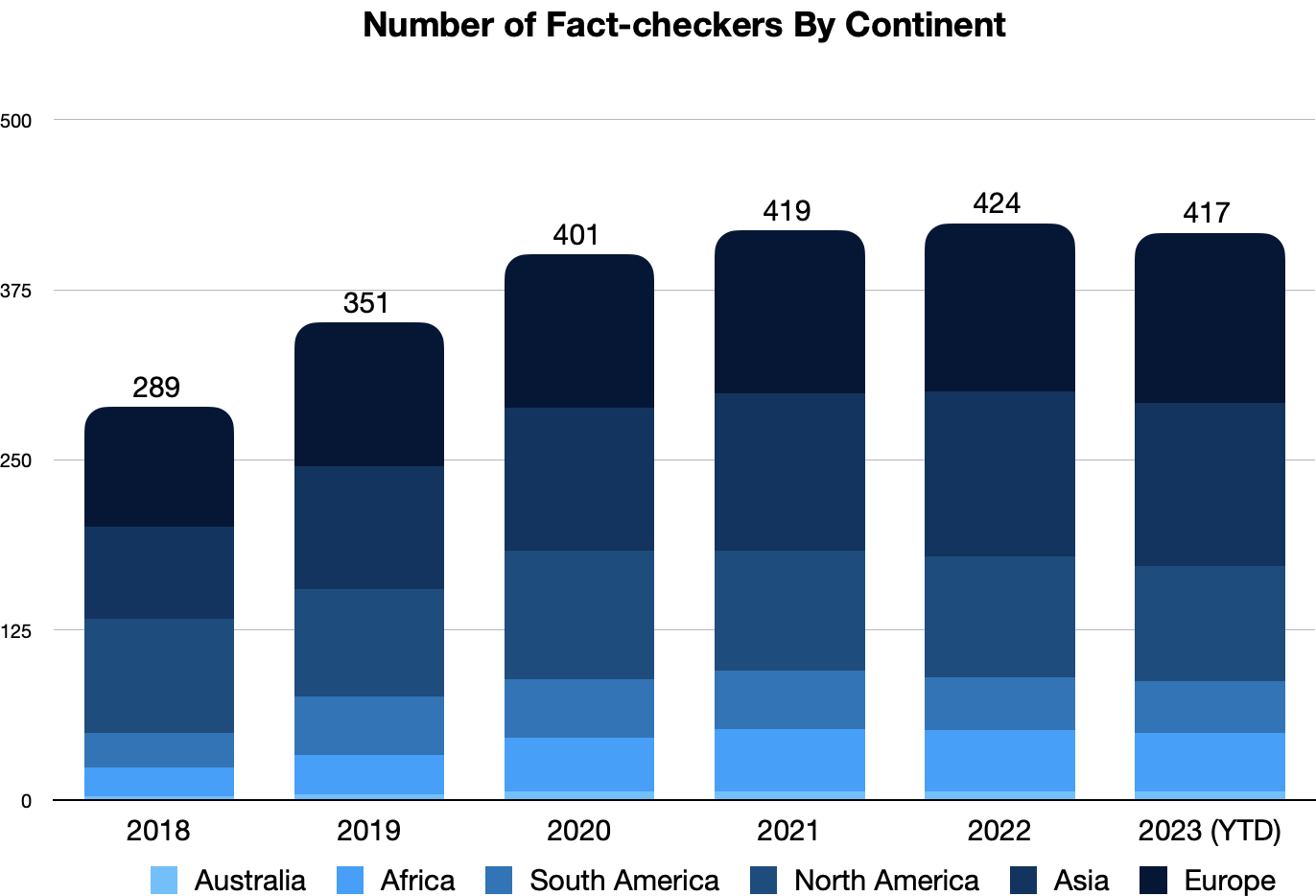
Chart of the week
The 10th annual fact-checking census from the Duke Reporters’ Lab showed that fact-checking has levelled off.
And one more thing
Elimin8Hate’s ReClaimYourName.dic, a custom dictionary to normalise Asian names, has been added to Microsoft 365 applications, according to the organisation’s press release. No more squiggly red lines under yours.

Not you calling out the Guardian 💀